January 16, 2026


Manufacturing organizations worldwide are grappling with a fundamental challenge: how to create unified, intelligent data infrastructure that enables both Digital Twins and AI at enterprise scale. While most companies have made significant progress in connectivity and data collection, the path from raw industrial data to actionable intelligence remains unclear.
This article presents a practical framework for leveraging ontologies and knowledge graphs as the foundational layer for industrial AI and Digital Twin implementations. The insights are drawn from in-depth conversations with leaders at tleading enterprise manufacturers, providing a rare view into how leading organizations are approaching this challenge.
The core thesis is clear: Knowledge graphs serve as the critical infrastructure layer that transforms fragmented industrial data into a unified, context-aware foundation upon which AI systems can effectively operate.
This document provides manufacturing data leaders, IT/OT architects, and digital transformation executives with a structured approach to implementing knowledge graph-based architectures, along with practical guidance on avoiding common pitfalls.
The Industrial Data Challenge
The Distributed Reality
Large manufacturing organizations face a common paradox: their distributed, autonomous decision-making culture has driven operational success, but that same autonomy has created significant data fragmentation. Production sites operate with independent architectural setups, different data management approaches, and isolated governance structures.
The challenge is not simply technical, it is organizational and cultural. Manufacturing companies must find ways to implement centralized governance without eliminating the local autonomy that enables operational agility. As one practitioner described it: "Our job from a central IT perspective is really to enable. We're trying to centralize to distribute, how do we centralize the minimum things we need to enable different teams and factories to work independently, while we keep the required governance that makes things interoperable."
The Interoperability Gap
Organizations typically excel at the factory floor level, advanced solutions exist for individual production units. However, scaling these capabilities across the enterprise reveals critical gaps:
- Inconsistent data definitions: The same term means different things across departments. A "part" in logistics differs fundamentally from a "part" in production, design, or embedded systems engineering.
- Context loss: Data extracted from its original environment loses the contextual information necessary for accurate interpretation and decision-making.
- Integration complexity: Connecting data across geographically distributed facilities with varying levels of automation maturity requires approaches that accommodate heterogeneity.
- Information ownership ambiguity: Identifying who owns, maintains, and is accountable for data quality across organizational boundaries remains a persistent challenge.
Understanding the Semantic Stack
Ontologies: The Schema Layer
An ontology provides the structural foundation, a schema that defines how concepts relate to one another. Unlike traditional database schemas that define data types and storage structures, ontologies capture the meaning of relationships between entities.
The ontology describes not just that Entity A is connected to Entity B, but how they are connected, why that connection matters, and what that relationship implies in different operational contexts.
Key characteristic: Ontologies are machine-understandable. Software systems can interpret the knowledge directly, enabling automated reasoning about relationships and dependencies.
Knowledge Graphs: The Instance Layer
While the ontology provides structure, the knowledge graph contains the actual data instances populated within that structure. The knowledge graph is the realized, living representation of your industrial knowledge; equipment, processes, relationships, and their interconnections.
The critical distinction: You create the ontology to define how things connect. You populate the knowledge graph with actual data to make those connections actionable.
Context fundamentally changes how data should be interpreted. Consider a component in a truck manufacturing environment:
- Logistics perspective: The part is a physical item with dimensions, weight, storage requirements, and supplier relationships.
- Production perspective: The part is an assembly target with installation sequences, tooling requirements, and quality specifications.
- Engineering perspective: The part is a design artifact with CAD models, material specifications, and performance parameters.
- Embedded systems perspective: The part contains electronic circuits with firmware, communication protocols, and integration requirements.
Knowledge graphs enable this multi-dimensional contextualization, the same underlying data can be viewed and interpreted correctly from each perspective, with the semantic layer maintaining the relationships and transformations between views.
Positioning in the Data Architecture
Relationship to Unified Namespace
Manufacturing organizations implementing Unified Namespace (UNS) architectures often ask: where do knowledge graphs fit? The answer is complementary, not competitive.
Unified Namespace provides a hierarchical structure for organizing real-time operational data. It establishes a well-defined structure that guides users to find data and understand its immediate context within the operational hierarchy.
Knowledge Graphs provide an enrichment layer that adds multi-dimensional context across domains. They extend the hierarchical view with cross-cutting relationships that span organizational boundaries.
Critical capability: Knowledge graphs enable data access without data movement. Rather than replicating data into centralized lakes, the semantic layer provides the intelligence to know where to go to fetch the right data and how to enrich real-time information with contextual data from other sources.
The Data Virtualization Approach
Leading organizations are implementing knowledge graph-based data orchestration that virtualizes data access rather than centralizing data storage.
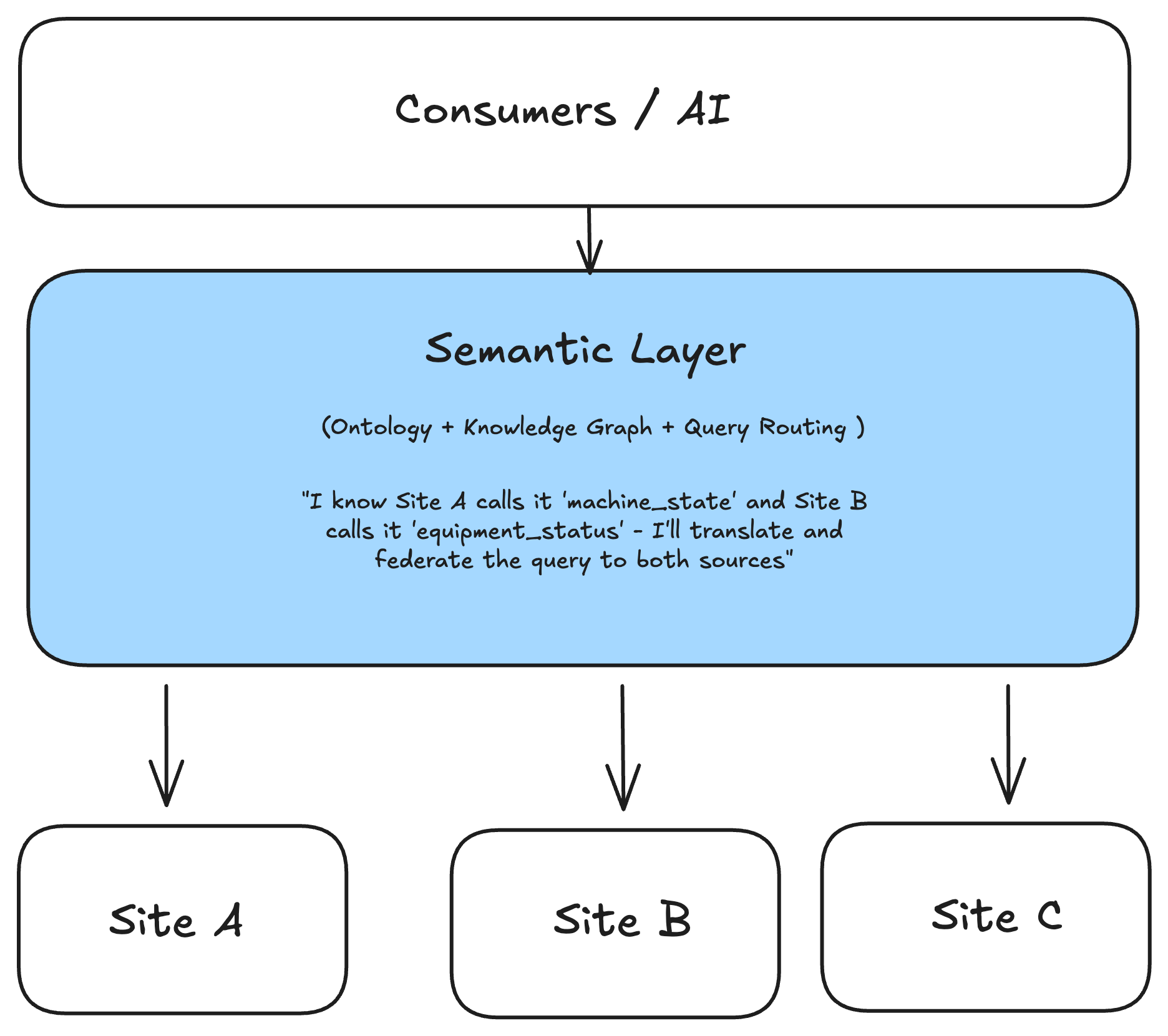
This approach enables:
- Complex data flows: Pull data from multiple sources, transform it, use the transformation results to fetch additional data, and deliver integrated results—all without persistent data movement.
- Self-service access: Business users can define data flows themselves while IT maintains central governance over the orchestration framework.
- Data sovereignty: Data remains at its authoritative source, eliminating synchronization challenges and maintaining clear data ownership.
Knowledge Graphs as Industrial AI Foundation
The Strategic Approach to Industrial AI
Mature manufacturing organizations have converged on a common AI strategy: leverage foundational models rather than building and training proprietary ones. The competitive advantage lies not in the models themselves, but in the proprietary data and knowledge that makes those models useful for specific industrial contexts.
This strategic reality elevates knowledge graphs from a "nice-to-have" data management tool to a critical competitive asset. The knowledge graph becomes the structured repository of institutional knowledge that enables AI systems to operate effectively within the company's specific context.
Enabling AI Capabilities
Well-structured knowledge graphs provide AI systems with:
- Process knowledge: Both administrative workflows and manufacturing processes documented in a machine-readable format that AI can consume and act upon.
- Relationship understanding: How components, systems, and processes interconnect, enabling AI to reason about dependencies and cascading effects.
- Contextual grounding: The semantic context necessary for AI outputs to be relevant to specific operational situations.
- Common vocabulary enforcement: Automated alignment of terminology and concepts across AI interactions.
The Emerging MCP Architecture Pattern
Leading organizations are now exploring how to expose manufacturing services through standardized protocols like the Model Context Protocol (MCP). The architectural pattern combines:
- Knowledge graphs containing process definitions and business logic
- MCP servers exposing manufacturing services as AI-consumable interfaces
- AI agents that understand processes and can invoke appropriate services to achieve objectives
This architecture enables AI systems to move beyond simple Q&A toward genuine process automation, understanding what needs to happen, which services must be invoked, and in what sequence.
Digital Twin Evolution Framework
The term "Digital Twin" suffers from significant definitional inconsistency across the industry. Many implementations are essentially real-time dashboards—useful, but falling far short of the technology's potential.
A mature Digital Twin architecture requires multiple integrated layers, with knowledge graphs providing the semantic foundation that connects them.

The Maturity Progression
Digital Twin implementations evolve through distinct capability levels:
Level 1 — Passive Monitoring: Real-time dashboards showing current equipment state. Valuable for visibility but reactive in nature.
Level 2 — Contextual Intelligence: Semantic layer adds relationship understanding. Users can trace dependencies and understand impact propagation.
Level 3 — Simulation Capability: Historical data combined with behavioral models enables scenario testing. Organizations can predict outcomes before committing to changes.
Level 4 — Autonomous Optimization: AI agents operating on the Digital Twin can proactively identify improvements, test scenarios, and—with appropriate governance—implement optimizations autonomously.
The vision: A factory that functions as its own optimizing entity—continuously evaluating possibilities, testing scenarios through simulation, and improving operations in a governed, autonomous manner. The Digital Twin becomes the authoritative source of truth, with physical operations executing what has been validated in the digital realm.
The Extensibility Advantage
Traditional database architectures require solutions to be designed based on anticipated requirements. When new dimensions emerge mid-implementation—and they always do—significant redesign becomes necessary. This creates a fundamental tension: the more comprehensive the initial design, the more rigid and difficult to change.
Graph-Based Flexibility
Knowledge graphs fundamentally change this dynamic. New dimensions, equipment types, or perspectives can be added by extending the graph rather than redesigning the solution. This enables organic growth:
- Begin with a single piece of equipment
- Extend to processes on the production line
- Expand to encompass the entire factory
- Scale to connect multiple facilities
- Integrate with enterprise-wide knowledge systems
Each extension adds to the existing graph without requiring modification of established structures. Different stakeholders can access the portions of the graph relevant to their perspective.
Implementation Framework
Successful knowledge graph implementations share common strategic characteristics:
Maintain data ownership: The knowledge layer and underlying data represent critical strategic assets. Architectural decisions must preserve organizational control over these assets, particularly as AI capabilities increase their value.
Favor composability over integration: Seek modular building blocks that can be assembled, rather than closed vertical solutions that control the entire stack. The goal is to leverage supplier functionality while maintaining architectural flexibility.
Use standardized components: Custom supplier solutions create long-term maintenance burden and update challenges. Where possible, leverage standardized offerings that can be replaced or upgraded independently.
Enable rapid adaptation: Market conditions, geopolitical factors, and competitive pressures require manufacturing organizations to respond quickly. Architecture must support this agility without sacrificing data governance.
Conclusion
The path from industrial data collection to enterprise AI capability requires more than incremental improvements to existing data management approaches. Knowledge graphs represent a fundamental architectural shift—from storing data to capturing knowledge, from rigid schemas to extensible semantic models, from data silos to connected intelligence.
For manufacturing organizations preparing for an AI-enabled future, the knowledge graph is not merely a technology choice, it is infrastructure for competitive advantage. The organizations that build robust semantic foundations today will be positioned to leverage AI capabilities as they emerge, while those who delay will face increasing gaps between their data assets and their ability to extract value from them.

Kudzai Manditereza is an industrial data and AI educator and strategist. He specializes in Industrial AI, IIoT, Unified Namespace, Digital Twins, and Industrial DataOps, helping manufacturing leaders implement and scale Smart Manufacturing initiatives.
Kudzai shares this thinking through Industry40.tv, his independent media and education platform; the AI in Manufacturing podcast; and the Smart Factory Playbook newsletter, where he shares practical guidance on building the data backbone that makes industrial AI work in real-world manufacturing environments. Recognized as a Top 15 Industry 4.0 influencer, he currently serves as Senior Industry Solutions Advocate at HiveMQ.
Stay up to date on the latest industry4.0 trends
Connect Online

