

OPC UA Information Model – How an OPC UA Information Model Works
In part one of this series, I introduced you to the OPC UA standard and highlighted information modeling as one of its pillars that make it well suited to become the de facto standard of industrial IoT information exchange. Now, the question is, why is data modeling so important for industrial IoT? To answer that question, let’s introduce the automation pyramid, which involves a strict flow of information up and down the pyramid through dedicated communication networks at each stage.
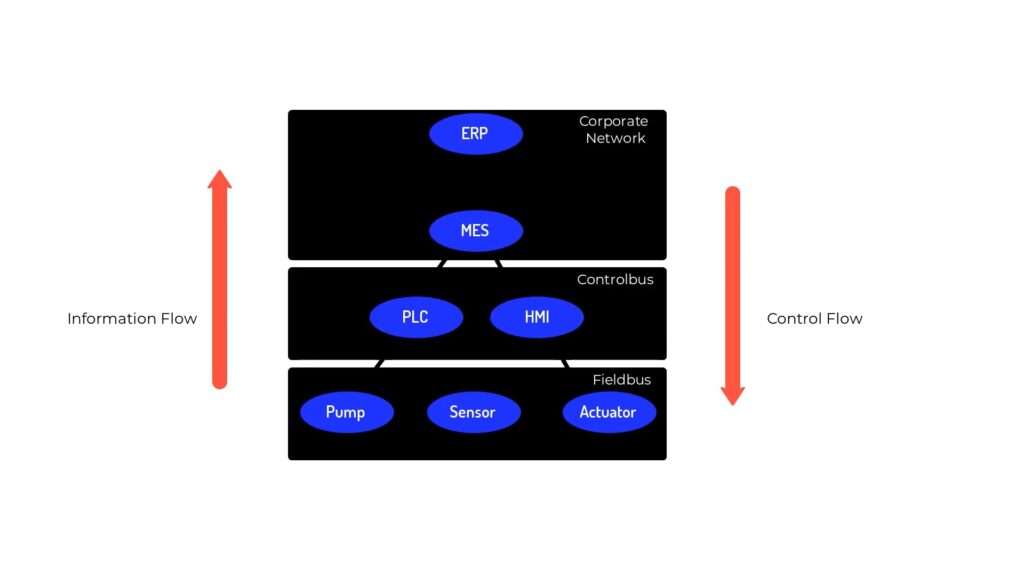
Now, with the introduction of industrial IoT communication standards that are common throughout these stages, there won’t be a need for these boundaries. Therefore, this rigid structure will inevitably decompose into decentralized components that are capable of flexible communication with each other.
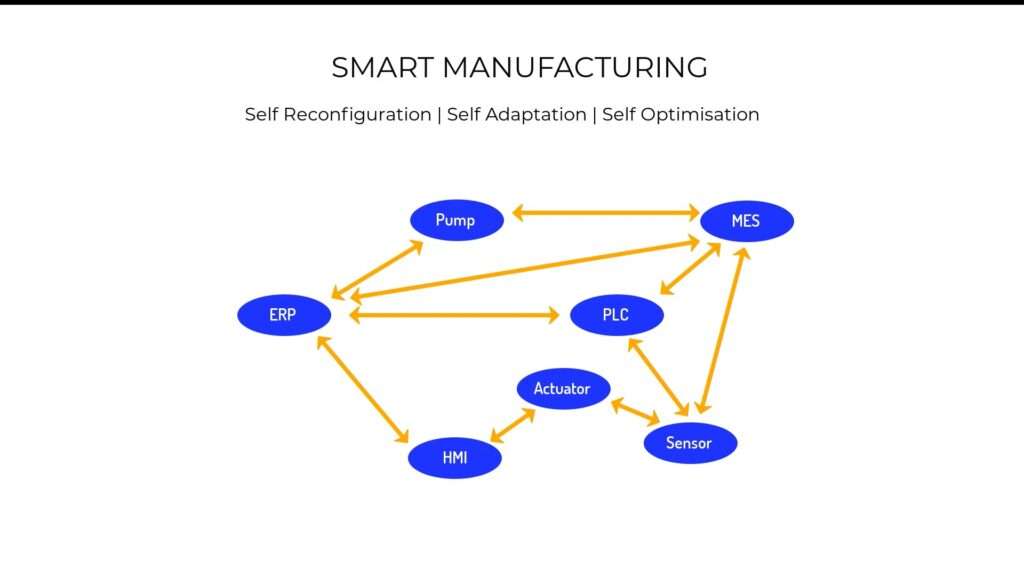
And when that happens, this stage will be set for smart manufacturing, because then all the components would be able to gather information from other components at any given time, and go on to autonomously reconfigure, adapt and optimize themselves accordingly based on that information, but yet, that can only happen if there is consistency in the presentation of information. In other words, the manner in which information is represented in an RP system must be the same manner in which information is represented in a field level sensor.
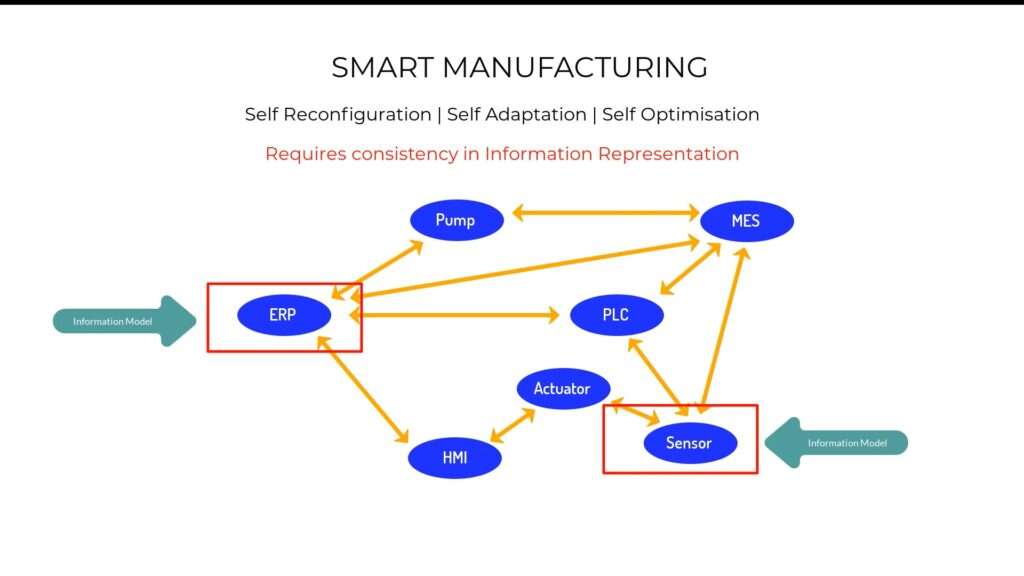
Hence, the reason why information representation or modeling is crucial for industrial IoT.
Now, because all these components are complex systems by nature, whatever information modeling approach you decide to use, it must allow you to digitally represent these production assets in their full complexity. This is where OPC UA Information Modeling comes in, as it gives you the ability to digitally describe components of a production asset in a standardized manner, such that any component consuming its information is given a holistic view of the underlying asset.
It should go without saying that, eventually, for your machine or plant to be able to interconnect with the rest of the industrial IoT ecosystem, it will be expected to expose its underlying information in a standardized manner.
But how do you even begin to represent such complex information? I mean, we are used to using simple information types, for example, an individual floating point variable to represent temperature.
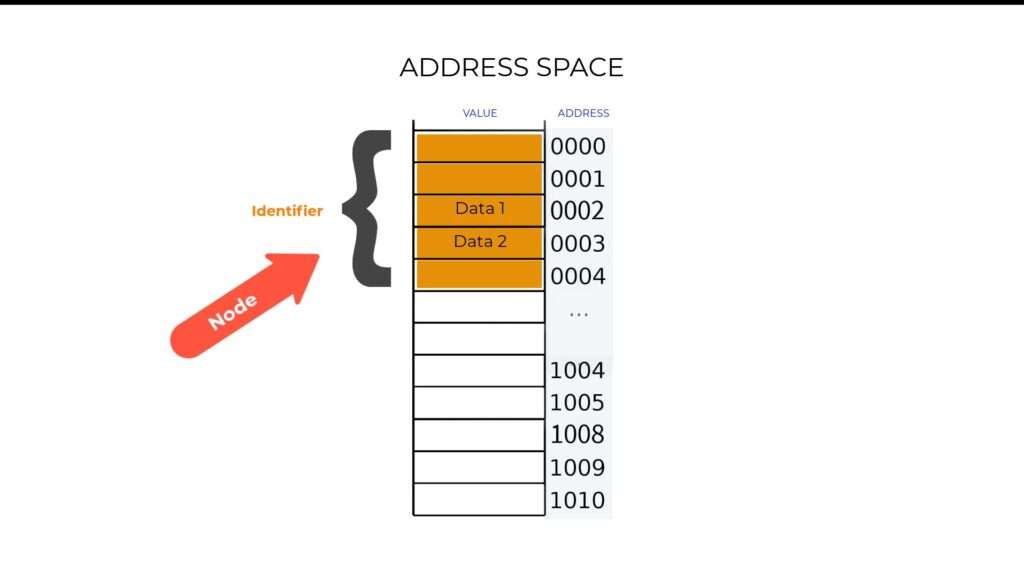
To explain, I’ll introduce the concept of an address space. Generally, to represent any kind of information in a computer system, you’d need space in memory to hold your data. This is called an address space.
Now, to represent simple information in address space, you just have to create a variable and provide its identity or name to any client interested in reading or writing is value. The identity would typically be a string variable that is unique throughout the address space, for example, temperature.

In order to use the same address space to represent complex information, OPC UA had to come up with a particular way of organizing data.
Specifically, instead of having a name such as temperature representing one float variable OPC UA has a group of different types of variables represented by a single name or identifier. This group of variables represented by a single name is called a Node, and it is the basic unit of information in OPC UA, every other type of information in OPC UA is built from a Node.
So, what is a Node composed of?
First there is information about the Node itself. For example, its name or identity. These are called attributes of a Node.
Second there is the actual data, which could be the value of temperature. And then there is also information about other nodes that it is related to. These are called references. So an OPC UA information model in this case, would be a collection of these nodes and their references.
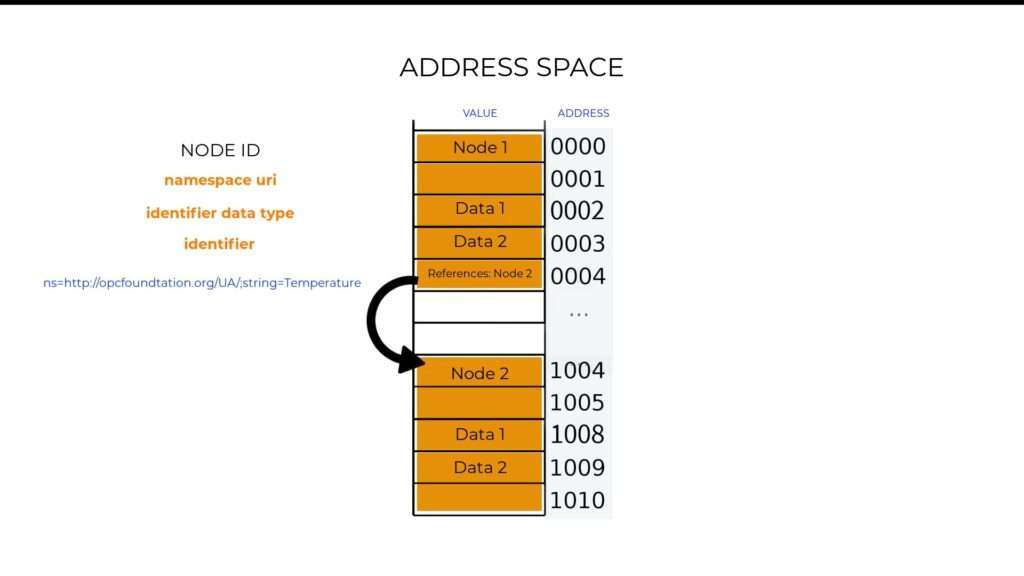
OPC UA doesn’t use simple string variables to represent the node identity. Instead, the Node ID consists of three parts. A namespace uri, the datatype of the identifier, and the actual identifier.
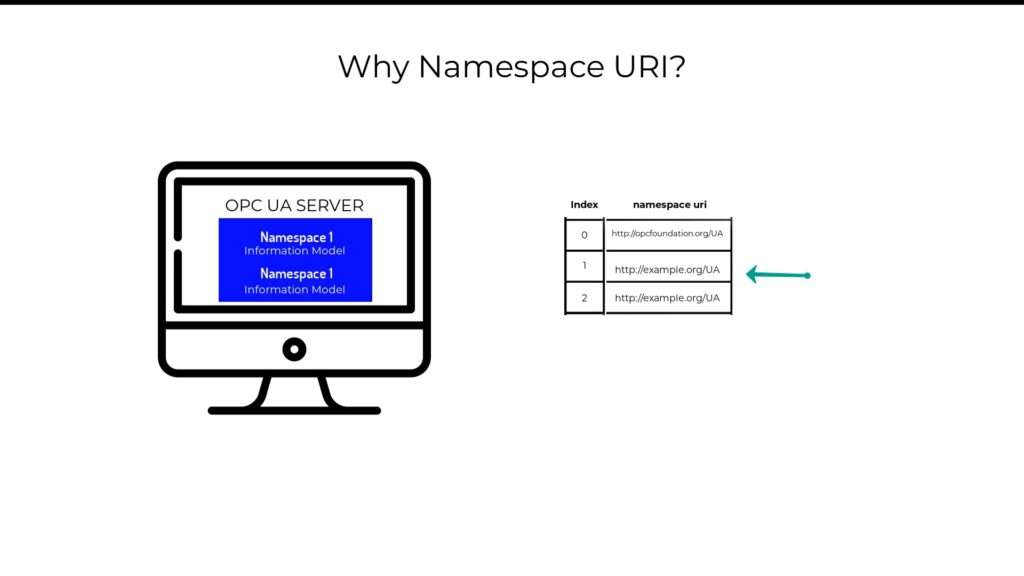
So ideally, your Node ID will look appear as shown in the above image. Whereby ‘ns’ stands for namespace string, ‘s’ the type of identifier used, and temperature as the actual identifier. But yet, because a namespace would be too long to use as the Node ID, the actual namespaces in your OPC UA server are stored in a table so that you only have to specify its index on that table, which would reduce your node ID to something like the image below.
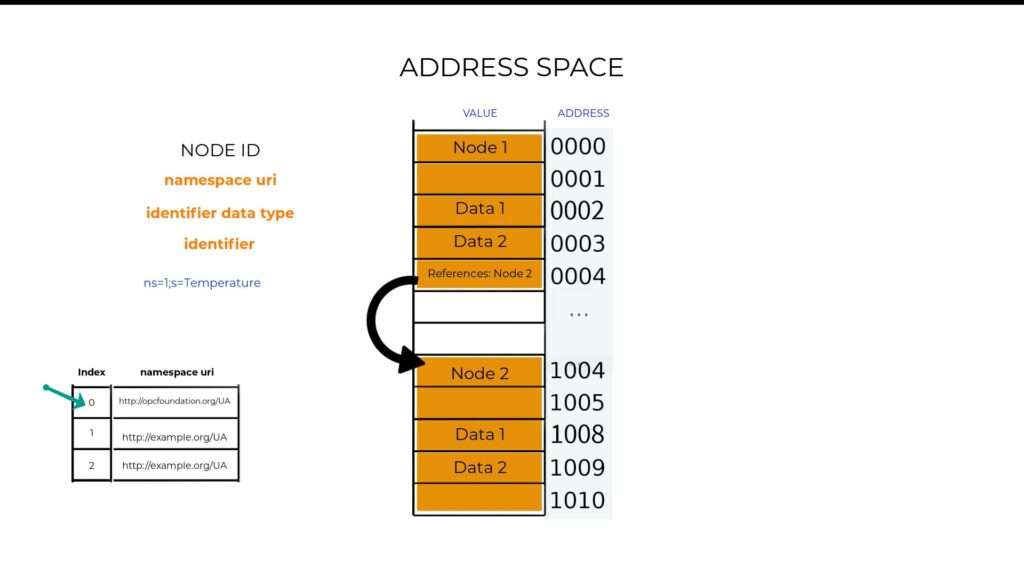
Where ‘s’ is short for string.
How is a namespace uri of any use?
Now, because each Node must belong to a namespace. It allows a single OPC UA server to expose different types of information models, whereby index zero, which stores the default namespace is always reserved for the OPC foundation based information model, while the other namespace indexes can be used by any other organizations that have information models specific to their industry verticals.
But still that doesn’t explain how you can be able to represent complex information on an OPC UA server.
As I mentioned before, a Node is a basic building block of an OPC UA information model. So to be able to build complex information out of a basic node, the node has to be able to take different shapes or forms. Take for example, when building a complex metal structure, you need different shapes of metal, you need a straight metal, you need an elbow metal, and a T shaped metal, but they all inherit the basic characteristics of a metal.
In almost a similar fashion. OPC UA borrows from a common technique in software development, called Object Oriented Programming, to specify different classes of nodes that all inherit the characteristics of a basic node. And these are the classes that are made available for you to design an information model for your machine, your plant or your software system, etc.
Let’s take a look at some of the node classes that are key to building an information model using OPC UA.
There is the Variable NodeClass, this is a class of nodes that hold actual data. And then you’ve got the Method NodeClass, and this is a class of nodes that are used to represent methods or functions that return a result when called by clients. And then next we’ve, got the Object NodeClass, and the object NodeClass is the key to understanding OPC UA information modelling because it represents real objects that you see when you look around a factory. This could be a pump, a compressor, a boiler, or the whole factory itself.

These real world objects share two characteristics. They have got state and behavior. For example, the state of a pump could be on or off, and the behavior could be starting the pump or stopping the pump.
OPC UA object nodes are similar to real world objects. They also consist of state and behavior. An OPC UA object node stores its state using variable nodes, and its behavior using method nodes.
And then, we’ve also got the ObjectType NodeClass. Now remember, the object node class that I just described, is used to represent real world objects. But yet, we know that in a factory, and in general, we can have more than one object of the same type. For example, you can have two pumps of the same type. Now to cater for that, the OPC UA object type node class allows you to define, for example, a specific type of pump object and then go on to create multiple instances or copies of that pump type.
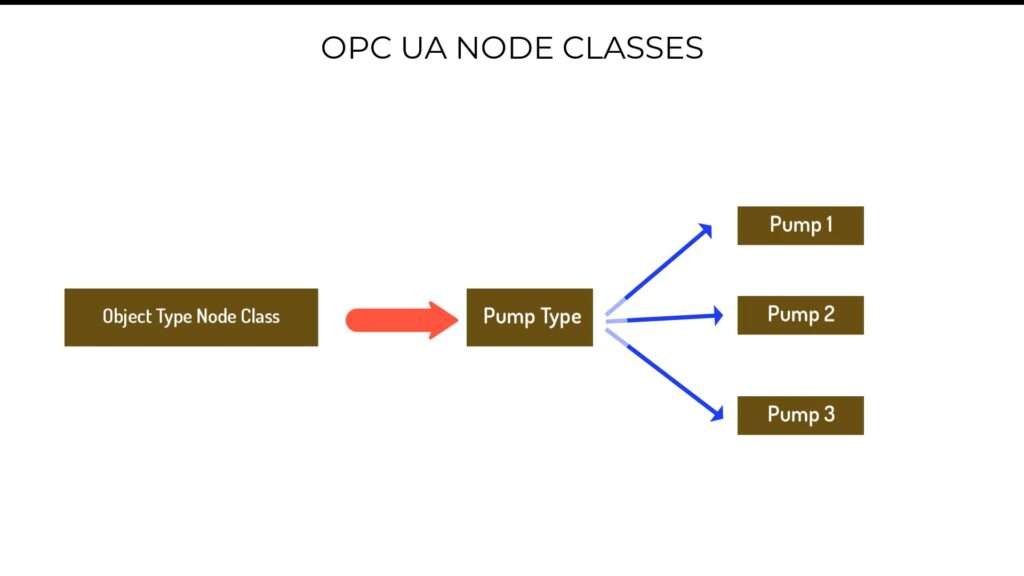
In object oriented programming, object types are the equivalent of classes. Now let’s take for example, if you are creating an OPC UA server to expose information of your plant, which has 10 pumps of the same type. Then, you’d begin by using the object node class to create a pump object. And then from the pump object, you will then create a pump type using the object type node class. Finally, you use the pump type class to instantiate 10 pumps of the same type.
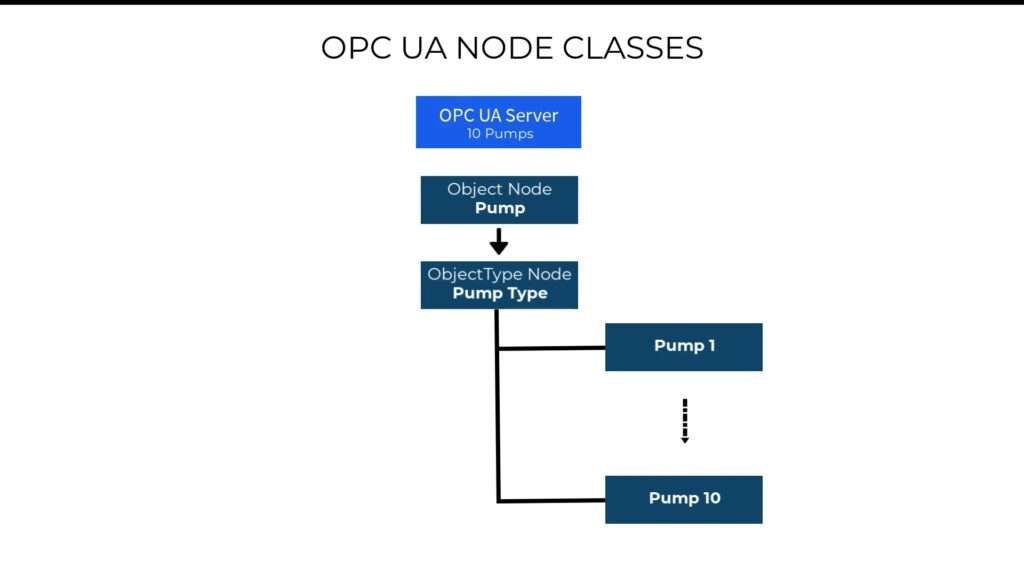
And then we move on to the ReferenceTypes NodeClass. So, we know that our pump type has on/off status, which can be represented by a variable node that stores a boolean value. And we also know that our pump type has Start and Stop behaviors, which can be represented by method nodes, with functions that can be called by a client.
Now the question is how do we link our pump type to these state and behavior nodes that are stored somewhere in the address space? We use Reference Type nodes.
Basically a reference type node contains information about how two nodes or objects are related.
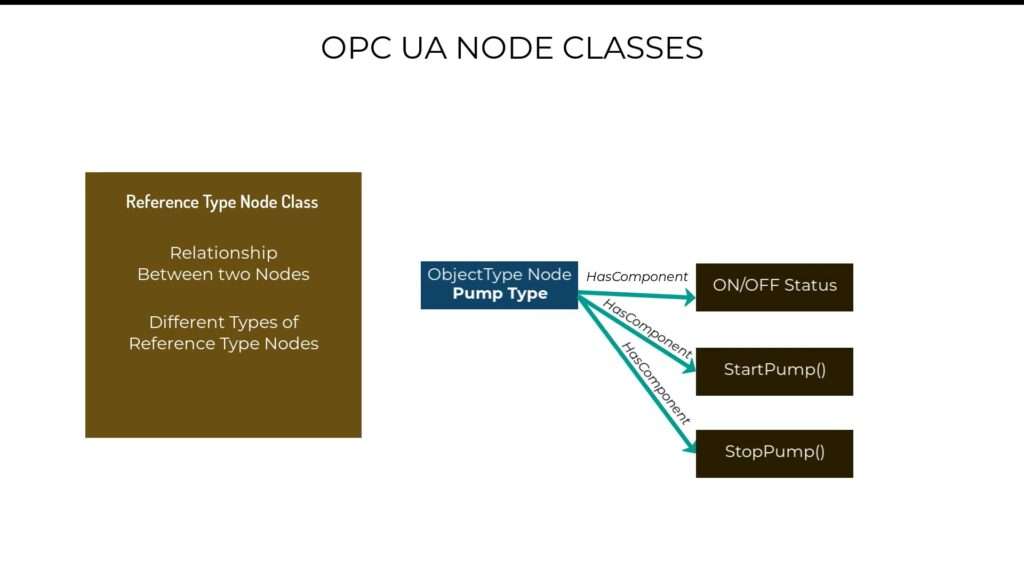
And because there are different types of relationships that two nodes or objects can have. There are also are different types of reference types nodes that you can use to define relationships between your objects. For example, one object can be a component of another object, which is the case with our on/off status node being a component of our pump type. So if that’s the case, then we use a HasComponent reference type for our pump type in order to specify that it has the on/off status node, and the start/stop nodes as its components.
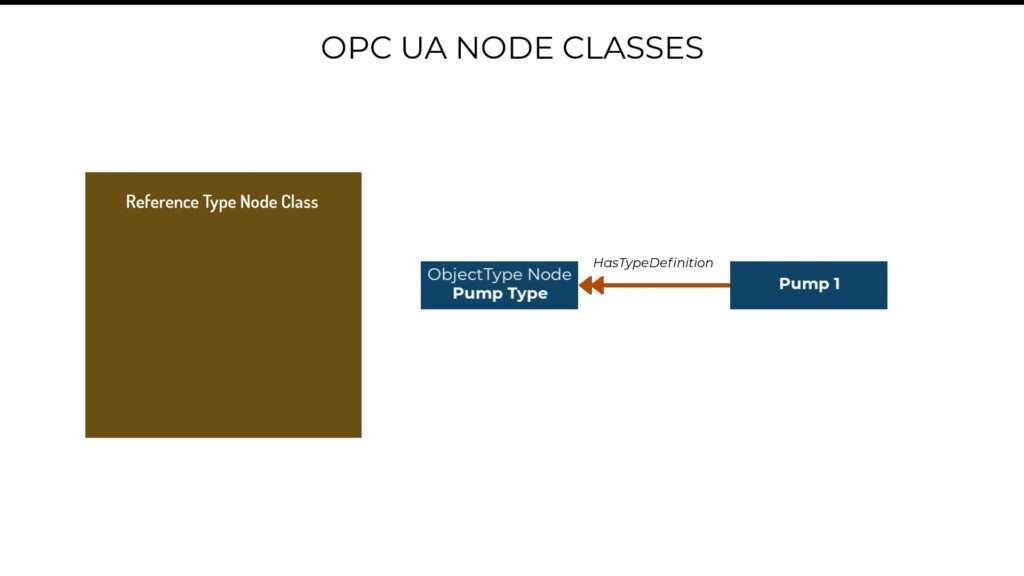
Now when it comes to creating an instance, or copy of our pump type, there is a way of specifying that our pump type as the parent of the created copy. And that is through the created copy using a HasTypeDefinition Reference Type to indicate the type of its parent.
If by any chance you’re finding this hard to grasp, don’t worry, it becomes clearer in part four of this series, where I show you how to actually create an information model.
To summarize, an OPC UA information model is a standardized definition of unique nodes in the OPC UA server address space. The uniqueness of the nodes is provided by the Node ID. And every object, device system, or even an entire factory can be represented using an interconnection of nodes and their relationships in OPC UA server address space.